
Итак, подводим итоги нашего октябрьского тест-конкурса в клубе КИТТ. В этом конкурсе приняли участие 54 человека и 2 нейросетевые системы ИИ — DeepSeek и QWEN. Список из 54 участников с благодарностью приводится в приложении.
Участники добровольно выполняли 2 процедуры (имели право выполнять только одну из двух):
- Шкалирование по 6 факторным шкалам «Большой шестерки» 30 мужских персонажей русской классической литературы.
- Шкалирование по 6 факторным шкалам «Большой шестерки» 30 женских персонажей русской классической литературы.
При этом список названий полюсов биполярных факторных шкал «Большой шестерки» выглядел следующим образом:
| Лживый, хитрый | Честный, порядочный |
| Спокойный, выносливый | Тревожный, эмоциональный |
| Интроверт, пассивный | Экстраверт, активный |
| Эгоистичный, холодный | Добрый, теплый |
| Импульсивный, рассеянный | Организованный, ответственный |
| Прагматичный, приземленный | Любознательный, романтичный |
Таблица 1. Названия полюсов факторных шкал. Применялись не классические (профессиональные) названия полюсов факторов HEXACO, а такие которые облегчают работу для непрофессиональных психологов.
Применялась пятибалльная шкала оценок с обозначением градаций в виде числовых значений от -2 до +2.
С мужскими персонажами участники оказались знакомы значимо лучше, чем с женскими. В этом случае мы получили 51 полный протокол (каждый протокол представлял собой двумерный массив оценок 6 строк на 30 столбцов). Средняя согласованность между респондентами (экспертная конкордация) в случае мужских персонажей оказалась равной 0,72, что следует признать вполне приличным уровнем согласованности. Только 4 человека из 51 «выпали из обоймы» — показали коэффициент согласованности «косинус» ниже 0,6 (это составило менее 8 процентов от общего числа оценщиков).
В случае женских персонажей мы получили меньше полных протоколов (только 41) и средняя согласованность оказалась ощутимо ниже (0,62). При этом 15 человек из 41 показали низкую согласованность — ниже 0,6 (это составило 37%).
ТЕПЕРЬ О ГЛАВНОМ — О СОРЕВНОВАНИИ ЛЮДЕЙ И МАШИН
Внимание: в обоих случаях по критерию «согласованность оценок» люди одержали победу. В случае мужских персонажей QWEN занял только 22-е место (со средним результатом), а DeepSeek оказался фактически в нижней группе — только 44-е место. В случае женских персонажей эти нейросети выступили несколько лучше QWEN занял 14-е место, а DeepSeek — 25-е место. Да и то надо сказать, что это более приличные результаты на женских персонажах машинам удалось получить только за счет таких персонажей, с которыми совсем плохо знакомыми оказались люди (все-таки маловато ярких и известных главных женщин-героинь оказалось в русской литературе по сравнению с героями-мужчинами). Если потратить больше времени на анализ результатов (времени, которого пока нет), то можно было бы исключить совсем малоизвестные женские персонажи и тогда результаты нейросетей оказались бы и в этом разделе нашего конкурса такими же низкими, как и в случае мужских персонажей.
ПРИЗЕРЫ КОНКУРСА
Как всегда это мы делаем в проекте КИТТ (в конкурсах с призами), мы получили по три призера в каждом отдельном из двух турниров, которые показали максимальную согласованность и получают небольшие призовые суммы.
Лучше всех оценили мужские персонажи:
Сорокина В.А., Борцова М.Е., Демидова И.
Лучше всех оценили женские персонажи:
Сорокина В.А., Куренкова А., Луговой А.
Итак, мы видим, что абсолютным победителем стала наша участница по фамилии Сорокина В.А. — она показала самую высокую согласованность своих оценок и в случае оценивания персонажей-мужчин, и в случае оценивания персонажей-женщин. Мы постараемся связаться с этим участником нашего проекта КИТТ и сообщить вам, существуют ли какие-то особенные обстоятельства и факторы, которые предопредили такую завидную регулярную точность оценок у нашего абсолютного победителя.
РЕЗУЛЬТАТЫ ПО ОТДЕЛЬНЫМ ФАКТОРАМ И ОТДЕЛЬНЫМ ПЕРСОНАЖАМ
Наша система Ht-Line 2.0 позволяет не только собрать результаты шкалирования, но и автоматически просчитать согласованность по отдельным факторным шкалами и отдельным объектам оценивания (в данном случае это персонажи). Знатоки понимают, о каком удобстве идет речь: ведь такой анализ «куба данных» оказывается весьма трудоемкой задачей даже при использовании таких эффективных программ как электронные таблицы MS Excel (не очень-то приспособленные для работы с трехмерными массивами данных «эксперты * объекты * шкалы»).
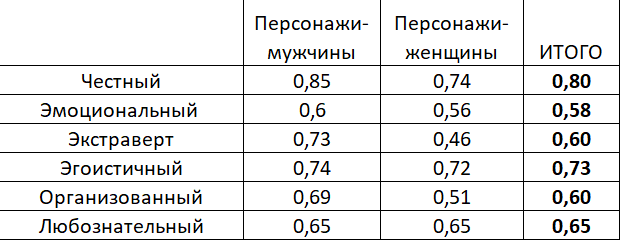
Таблица 2. Данные о согласованности по факторным шкалам.
Какую закономерность мы усматриваем в таблице 2? Наиболее важными наблюдаемыми факторами в русской классической литературе оказались факторы 1 Честность (Honesty) и 4 Согласие (Agreeableness). Это полностью соответствует традиционным литературоведческим (культурологическим) взглядам на русскую классическую литературу, в которой фактор «Моральная Оценка» всегда оказывался доминирующим в оценке человека человеком.
Несколько более неожиданными и трудным для поспешной интерпретации является такой факт, что в случае женских персонажей значимо более слабую согласованность наши участники-эксперты продемонстрировала в своих оценках по факторной шкале «Экстраверсия — Интроверсия», Возможно, кто-то из читателей поделится в комментариях своими соображениями, как это можно объяснить. Тем более, что в случае с мужскими персонажами такая закономерность не прослеживается вовсе (в этом случае по уровню согласованности фактор «Экстраверсии» оказывается на вполне почетном третьем месте среди всех шести факторов).
Интересно заметить, что ни по одной из шести факторных шкал наши «машинные эксперты» не оказались даже в тройке лучших оценщиков. Лучшее достижение — это 8 и 6 места у системы QWEN по фактору «Согласие» в случае мужских и женских персонажей соответственно.
Несколько более заметными оказались достижения «машин» по отдельным персонажам.
DeepSeek лучше всех оценил такого сложного литературного героя как Печорин, а также занял почетное второе место при оценивании женского персонажа Маргарита («Мастер и Маргарита»).
QWEN лучше всех оценил Петра Гринева («Капитанская дочка») и Агафью Пшеницыну («Обломов»), а также занял почетное второе место при оценивании Герасима («Муму») и профессора Преображенского («Собачье сердце»).
Примерно такими же успехами в случае отдельных персонажей может похвастаться добрая половина наших экспертов. Никакой особой закономерности в достижениях «нейросетей» я не могу усмотреть.
Гораздо интересней и богаче для интерпретации мне показались интегральные показатели согласованности (по всем экспертам). Весьма примечательно, по каким персонажам нашим участникам оказалось добиться высокой согласованности. Первое место из 30 мужчин занимает Данко («Старуха Изергиль» Максима Горького). Ну и понятно. Это самый схематичный, то есть во многом искусственный и сказочный герой. По нему коэффициент согласованности превышает 0,9 (!). Это даже выше, чем средняя согласованность по факторной шкале «Честность». Также высокую согласованность выше 0,8 мы наблюдаем для таких положительных персонажей как Николай Ростов (0,86), Петр Гринев (0.86), Владимир Ленский (0.83); Андрей Болконский и Пьер Безухов («Война и мир») набрали по 0,80. По сравнению с однозначно положительными героями низкую согласованность эксперты показывают в ходе оценивания таких сложных, неоднозначных персонажей как Евгений Онегин (0.43) и Григорий Печорин (0,45). Хотя… по рассогласованности этих «лишних людей» превзошел Манилов («Мертвые души» , коэффициент только 0,29).
КЛАСТЕРИЗАЦИЯ ПЕРСОНАЖЕЙ
Наш сервис-модуль «Шкалирование» включает такой аналитический режим как «Кластерный анализ» объектов шкалирования. Сразу видно, что некоторые полученные кластеры существенно отличаются от той дендрограммы, которая презентирована в нашей прежней публикации по этой теме:
Существуют, как минимум, 2 причины, объясняющие полученные различия:
- В прежней публикации были задействованы 40 разных шкал для оценивания персонажей, а здесь только 8 факторных шкал.
- В данном случае в выборку информантов-экспертов вошли не только психологи, но большинство активных участников КИТТ — это все-таки непсихологи (за многие годы мы знаем уже многих активистов клуба по их ФИО, ведь они становились неоднократными призерами наших конкурсов).

Таблица 3. Результаты кластерного анализа 30 мужских персонажей.
Занятными и в целом понятными я считаю в таблице 3 следующие кластеры:
Онегин и Печорин — «лишние люди»,
Безухов и Обломов — «мягкотелые добряки»,
Чичиков и Молчалин — «хитрованы-приспособленцы»,
Хлестаков и Шариков — «пройдохи».
К сожалению, у меня в эти дни не хватает свободного времени. Впрочем, Вы вполне можете продолжить давать интерпретирующие ярлыки этим кластерам самостоятельно.

Таблица 3. Результаты кластерного анализа 30 женских персонажей.
В случае с женскими персонажами сразу бросается в глаза кластер из трех отрицательных персонажей: Кабаниха, Элен Курагина, Софья Фамусова.Ну а остальные кластеры… Предлагаю Вам подумать над ними самостоятельно и постараться дать им интерпретирующий ярлык в своем комментарии к этой статье.
ОБЩИЕ ВЫВОДЫ
Как Вы это поняли из заголовка, основной целью нашего исследования стало «соревнование людей и машин». По результатам этого соревнования мы видим, что пока еще нейросети серьезно УСТУПАЮТ людям в точности и согласованности своих оценок. Причем уступают они прежде всего экспертным коллективам — вы данном случае такому коллективу, в котором присутствуют психологи, владеющие профессиональным категориальным аппаратом HEXACO («Большая Шестерка»). Поэтому такие системы, основанные на экспертных оценках специалистов, как, например, наша система ТЕЗАЛ, обладают определенными содержательными преимуществами.
Вы можете усомниться в победе людей или как-то принизить пафос этой победы, да? Но… сам перечень из 30 мужских и 30 женских персонажей был сгенерирован для этого конкурса на людьми, а именно «машинами» (!).
ПЕРСПЕКТИВЫ
Мы планируем расширить за счет литературных персонажей контент-базу нашей системы ТЕЗАЛ — системы, помогающей проинтерпретировать результаты тестирования и ассессмента. Литературные персонажи станут очередной самостоятельной факторно-категориальной системой (наряду с архетипами, зодиакальными психотипами, киноактерами и т.п.) — по счету под номером 19.
Уже сейчас участники клуба КИТТ могут выполнять в своем личном кабинете особый тест «Я в литературном пространстве». Результаты выполненного шкалирования позволяют уточнить созданные для этого теста ключи. Вход в клуб на официальном сайте клуба:
ПРИЛОЖЕНИЕ
Список участников клуба КИТТ, давших шкальные оценки литературным персонажам (в некоторых случаях мы не знаем ничего об участникам кроме псевдонимов или имен без фамилии, ну тогда желающим найти себя в этом списке придется немного… напрячься):
Evg , Gob Д.А. , Анд Д. , Ани Н.И. , Бел А.В. , Бор М.Е. , Вав Е.А. , Вик Н.В. , Гав А.В. , Дав Е.А. , Дем И. , Ден К. , Ден Т.Е. , Дер О.В., Зав Н.С. , Зот Н.В. , Ири, Коз Н.И. , Кок А. , Кок С. , Кош А.Н. , Кур А. , Леж Е.А. , Лом Е.А. , Луг А. , Лял Н.В. , Мак О.Н. , Мар, Мар Ю.М. , Мин О.И. , Оле, Оре Е.Ю. , Пав , Пет Д.В. , Пет А.В. , Про, С. А.В. , Сад Н.А. , Све С.С. , Сим А.А. , Смо Я. , Сор В.А. , Стр И. , Сум И.Н. , Сыч О. , Ток Д. , Уча Л. , Хаб Ю.Г. , Чер Т.А. , Шев А.А. , Юди Е.В. , Юрч О.Ю. , Юта
Добавить комментарий