Этой зимой мы планируем, как всегда это было в последние годы, провести Зимнюю Дистанционную Психометрическую Школу (ЗПМШ). У нас есть 2 альтернативные программы (с небольшим набором ядерных повторяющихся дистанционных лекций):
- Психометрика кадровых конкурсов (эта больше для эйчаров-аналитиков-менеджеров).
- Конструирование тестов знаний (эта больше для вузовских преподавателей и экспертов-предметников).
Смотрите программы этих дистанционных курсов на нашем сайте www.ht-line.ru.
Пока еще не ясно, по какой из двух тем мы получим больше заявок. Но уже сейчас хотелось бы анонсировать новшество. В любую из этих двух программ я планирую внедрить новое практическое упражнение:
«Экспертные классификационные опросы и автоматическое построение иерархической классификации с помощью кластерного анализа» (фу, длинноватое название получилось, но не вижу смысла делать его кратким пока что).
Суть этого упражнения Вам сегодня предлагается осмыслить на практическом примере (заодно, возможно, Вам станет интересным записаться на полную программу дистанционного курса).
Таким образом, прошу поучаствовать в следующем опросе:
Тест «Опрос «Классифицируем 20 форм правления»»
Я считаю, что в нашей «школе» могут участвовать с пользой для себя не только психологи, поэтому сознательно выбрал для примера не психологический материал, а несколько более общезначимый. Поясню также, что для меня «психометрика в оценке персонала» — это синоним «тестологии». А тесты могут и должны быть вовсе не только психологическими (например, тесты на профессиональные знания и умения в рамках какой-то профессии или отрасли).
Что же такое кластерный анализ результатов экспертных опросов? В чем тут специфика? Какие ошибки предстоит скорректировать, какие новые когнитивные навыки сформировать?
Частенько такая методика опроса, с которой я Вас здесь знакомлю, называется «свободная сортировка объектов», или точней — «сортировка карточек с названиями объектов». Важно подчеркнуть, что основания для классификации формулирует для себя сам эксперт (испытуемый). Как впрочем, он сам решает, сколько именно классов надо выделить.
Типичная ошибка начинающих в этом случае заключается в том, что результаты классификационного опроса фиксируются в виде неправильной, нерациональной табличной записи:
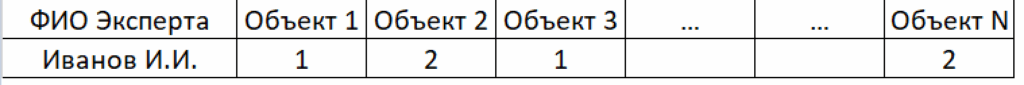
В клеточках такой таблицы указывается номер образованного экспертом класса объектов. В этом примере объекты номер 1 и номер 3 принадлежат классу 1, а объекты номер 2 и номер N — классу 2.
Важно уяснить такую «техническую детальку»: такая неправильная запись ЗАКРЫВАЕТ возможность для автоматизированного применения программ кластерного анализа. Важно использовать двоичную кодировку каждого класса, а не нумерацию классов в одной таблице. Такая двоичная кодировка приводит к образованию двух ключевых промежуточных структур для последующего анализа данных:
1) Двоичный протокол. В этом случае таблица, аналогичная указанной выше, должна иметь не меньше двух строк (в общем случае M строк по количеству классов, указанных одним экспертом). Вот какой вид она должна принимать:

Если все такие строчки, порожденные разными экспертами (респондентами), ввести в исходную таблицу данных друг под другом, то тогда алгоритм кластерного анализа (например, в рамках пакета SPSS) уже сможет быстро рассчитать попарное сходство между объектами (грубо говоря, мера сходства должна будет отражать частоту попадания пары объектов в один класс).
К сожалению, именно этому вопросу — правильной группировки первичных данных — очень мало уделяют внимания при обучении статистике (анализу данных) в большинстве вузов. Обычный акцент делает на формулах, но, с моей точки зрения, самый дефицитный момент — это правильная работа со структурой входных данных.
2) Матрица бинарных отношений. Каждую классификацию (в том числе на пересекающиеся классы) можно изобразить в виде матрицы бинарных отношений, в клеточке которых единица обозначает вхождение пары элементов (по строке и столбцу) в один класс, а нуль — попадание в разные классы. Вот пример того, как выглядит такая простейшая матрица бинарных отношений (пример синхронизирован с предыдущим «двоичным протоколом»):
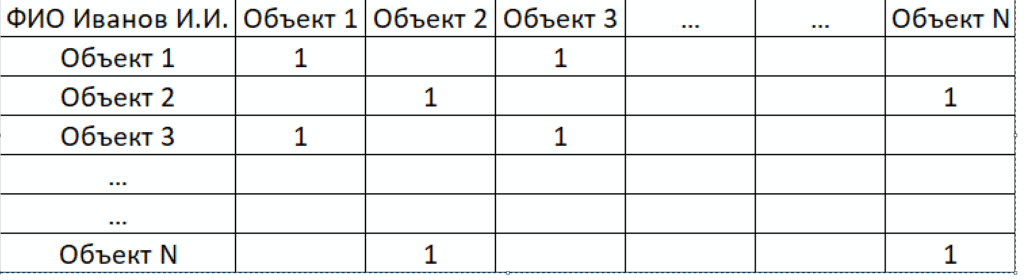
В этой матрице для наглядности я вместо нулей оставил пропуски. Мы видим в ней, что единички, конечно, стоят по всем клеточкам главной диагонали (ну это потому, что сам объект заведомо попадает в один класс «с самим собой», то есть отношение классификации является в математическом смысле «рефлексивным»). Первый класс в данном случае проявляет себе так, что 1 стоит на пересечении строки 1 со столбцом 3 (и симметрично — на пересечении строки 3 со столбцом 1, так как отношение классификации в математическом смысле является «симметричным»). Аналогично класс номер 2 проявляется в том, что единица стоит на пересечении второй строки и столбца номер N. Ну и так далее.
Зачем забивать себе голову освоением матрицы бинарных отношений? — спросите Вы. Отвечаю (как опытный преподаватель высшей школы, руководивший множеством курсовых и дипломных работ студентов и аспирантов, где применялся данный метод). Все дело в том, что без понимания этой особой структуры данных не освоить то, что называется «матрицей смешения» (если хотите «матрицей сопряженности»). Если произвести поклеточное суммирование таких К бинарных матриц, полученных от K экспертов, то при полном совпадении мнений относительной какой-то пары объектов, в соответствующей клеточке должно появиться число К (а если это выражать на шкале «процент совпадений», то будет число 100%). А вот если пару объектов зачислила в один класс только половина из К экспертов, то в клеточке появится число К/2 или в процентах — 50%.
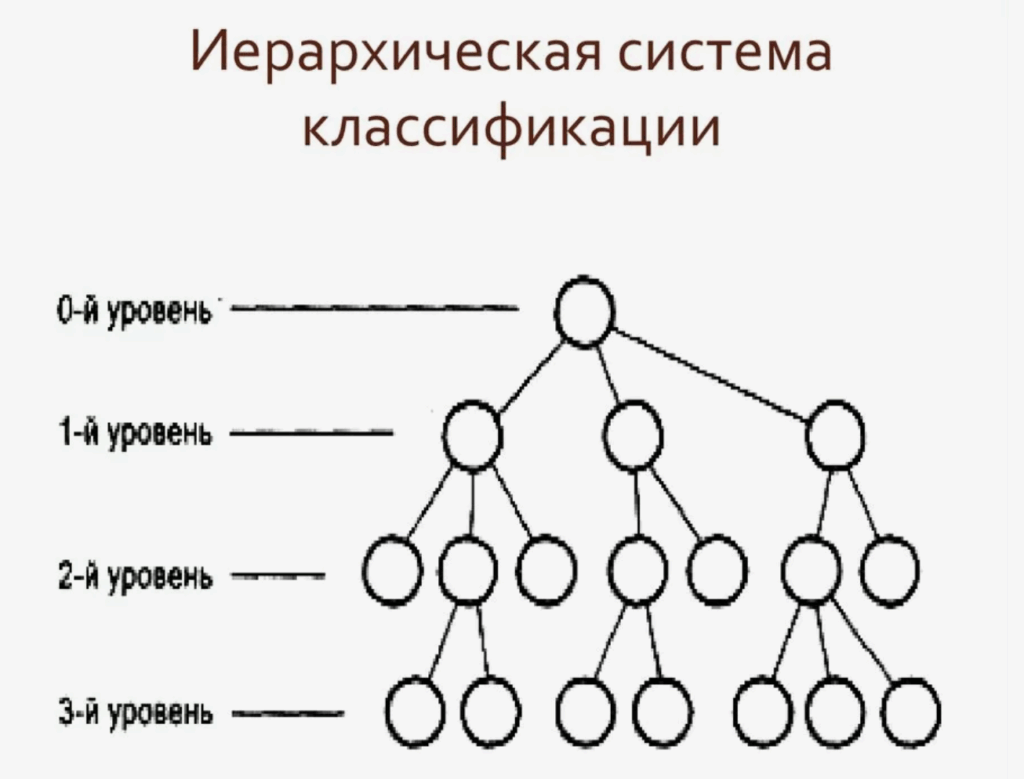
Еще раз: очень важно осмыслить, что алгоритмы иерархической классификации работают именно с «матрицами смешения»! — Они объединяют пары объектов в кластеры тем раньше (еще на нижних этажах иерархии), чем выше коэффициент сходства для данной пары объектов.
Где такой подход я сам применял совсем недавно на этом блоге? — Коллеги, перечитайте еще раз мои публикации насчет «зодиакальных персонажей». Я там писал, что входными данными для кластерного (да и факторного анализа) послужили в моем эксперименте именно «матрицы смешения». Да и к литературным персонажам вполне применима точно такая же методика (хотя до настоящего времени была применена другая методика — а именно методика «шкалирования», а не методика «свободной сортировки»).
ГДЕ ЭТО ПРИМЕНЯЕТСЯ?
Многие наши «гуманитарные специалисты» даже после освоения какой-то математизированной процедуры не могут обобщить полученный навык — перенести его из какой-то одной области (на которой реализован учебный пример) в ту область, с которой они сами работают. Это и есть причина множества разочарований, то есть наблюдаем трудности формирования обобщенной ориентировочной основы действия — так называемой ООД (использую терминологии Петра Яковлевича Гальперина, автора теории поэтапного формирования умственных действий). Без такой ООД перенос алгоритма (навыка) в интересующую Вас область оказывается невозможным. Но… Я в краткой статье не могу Вас научить выполнять такой перенос. Это как раз можно добиться в «школе», хотя тоже не в групповом режиме обучения. Перенос — такая деликатная процедура, которая требует индивидуального наставничества (когнитивного коучинга, как модно было бы сейчас выражаться, хотя я бы предпочел по-старинке говорить о «методическом консультировании»).
Но все-таки давайте перечислим хотя бы коротко (хотя бы в виде назывных предложений), где именно работает данная методика «свободной сортировки объектов» (и последующего кластерного анализа):
- При конструировании тестов знаний. Допустим, Вы уже имеете названия каких-то разделов возможного теста знаний. Допустим, что их 10 или даже 20, но Вам хотелось бы, чтобы тематических субтестов было не больше 5. Тогда Вы опрашиваете экспертов так, чтобы получить обоснованным образом 5 классов — более крупных тематических разделов. Понятный пример?
2. Ваши эксперты решали определенный значимый управленческий кейс и породили 20 вариантов решения (!). Некоторые формулировки очень похожи, то есть по смыслу «об одном», но формально они различаются. Ваша задача: опросить этих экспертов формализованным образом так, чтобы без внедрения собственных представлений в результат получить именно 5-7 (лучше не больше семи) возможных стандартных решений созданного задания для кейс-теста.
3. Ваши эксперты (пусть они же — это высшие руководители организации-заказчика) дают несколько РАЗНЫХ классификаций своих линейных руководителей и ключевых сотрудников в компании. Они по-своему дают названия этим разным классам, которые порождают. Они начинают даже страшно спорить друг с другом. Ваша задача: постараться погасить споры и применить конструктивную и объективную процедуру, которая может «вытащить» нечто общее из разных классификаций, которые кажутся, на первый взгляд, такими противоречивыми. Допустим, у Вас только три эксперта, но… Уже в этом случае описанная мной методика имеет смысл и может Вам дать очень полезный продукт: Вы получите нечто общее для всех трех экспертов, то есть такие кластеры, которые не будут охватывать, возможно, всех ключевых сотрудников, но по крайней мере дадут возможность НЕ потерять из виду некие «очевидные и типичные объединения». На основании этих кластеров можно уже строить «типовую модель компетенций» — анализировать психические и производственные качества сотрудников, вошедших в устойчивые кластеры.
Ну, наверное, достаточно примеров, да?
* * *
Итак, если Вам стало немножко интересно освоить эту «кухню» (она совсем несложная, но как всегда требует освоения какого-то небольшого набора новых понятий и представлений), то, пожалуйста, выполните предложенную выше процедуру — классификацию 20 «форм правления». Именно тогда Вам станет интересно почитать вторую статью на этом блоге по этой теме — ту будущую статью, где я представлю полученные результаты в виде дерева (дендрограммы), классифицирующей формы правления. Еще раз повторяю здесь ссылку:
Тест «Опрос «Классифицируем 20 форм правления»»
Надеюсь, что соберем на этот опрос достаточно ответов и опубликуем здесь не только дендрограмму, но и матрицу смешения 20 на 20 (!).
Добавить комментарий